

För två år sedan meddelade före detta president Barack Obama Precisionsmedicin initiativ i sin unionsadress Initiativet strävade efter en "ny era av medicin" där sjukdomsbehandlingar kunde anpassas specifikt till varje patients genetiska kod. ![]()
Detta resonerade soundly i cancermedicin. Patienter kan redan hantera sin cancer med terapier som riktar sig mot specifika gener som förändras i deras speciella tumör. Exempelvis behandlas kvinnor med en typ av bröstcancer orsakad av amplifieringen av gen HER2 ofta med en terapeutisk kallad herceptin. Eftersom dessa riktade terapier är specifika för cancerceller tenderar de att ha färre biverkningar än traditionella cancerbehandlingar med kemoterapi eller strålning.
Sådana behandlingar är emellertid inte tillgängliga för de flesta cancerpatienter. I många cancerformer är de specifika genetiska förändringarna som är ansvariga för en cancer okänd. För att skapa individuella cancerbehandlingar måste vi veta mer om de funktionella genetiska förändringarna.
Med data om cancergenetik växer snabbt kan matematik och statistik nu låsa upp de dolda mönstren i dessa data för att hitta de gener som är ansvariga för en persons cancer. Med denna kunskap kan läkare välja lämpliga behandlingar som blockerar verkan av dessa gener för att personifiera terapier för enskilda patienter. Min forskning syftar till att förbättra precisionsmedicin i cancer - genom att bygga på samma metoder som har använts för att hitta mönster i Netflix-filmbetyg.
Siffror genom data
Idag finns det oöverträffad allmän tillgång till cancergenetikdata. Dessa data kommer från generösa patienter som donerar sina tumörprover för forskning. Forskare tillämpar sedan sekvenseringsteknik för att mäta mutationerna och aktiviteten i var och en av 20,000-generna i det humana genomet.

Alla dessa data är ett direkt resultat av Human Genome Project i 2003. Det projektet bestämde sekvensen för alla gener som utgör sunt humant DNA. Sedan projektet avslutats har kostnaden för sekvensering av det mänskliga genomet mer än halveras varje år, överträffar tillväxten av datakraft som beskrivs i Moores lag. Denna kostnadsminskning möjliggör forskning för att samla in tidigare genetiska data från cancerpatienter.
De flesta vetenskapliga studier om cancergenetik som utförs över hela världen släpper ut sina data till en centraliserad, offentlig databas som tillhandahålls av National National Institute of Health (NIH) National Library of Medicine. NIH National Cancer Institute och National Human Genome Research Institute har också fritt släppt genetiska data från över 11,000-tumörer i 33-cancertyper genom ett projekt som heter Cancergenomatlasen.
Varje biologisk funktion - från att extrahera energi från mat till läkning av ett sår - beror på aktivitet i olika kombinationer av gener. Cancers kapar genen som gör att människor kan växa till vuxenlivet och som skyddar kroppen från immunsystemet. Forskare dubbar dessa "Kännetecken för cancer". Denna så kallade gendysregulering möjliggör att en tumör växer okontrollerbart och bildar metastaser i avlägsna organ från den ursprungliga tumörplatsen.
Forskare använder aktivt dessa offentliga data för att hitta uppsättningen genförändringar som är ansvariga för varje tumortyp. Men detta problem är inte så enkelt att identifiera en enda dysregulerad gen i varje tumör. Hundratals, om inte tusentals, av 20,000-generna i det humana genomet dysregleras i cancer. Gruppen av dysreglerade gener varierar i varje patients tumör, med mindre uppsättningar vanligt återanvända gener som möjliggör varje cancermärke.
Precisionsmedicin bygger på att hitta de mindre grupperna av dysreglerade gener som är ansvariga för biologisk funktion i varje patients tumör. Men gener kan ha flera biologiska funktioner i olika sammanhang. Därför måste forskare avslöja en uppsättning "överlappande" gener som har gemensamma funktioner i en uppsättning cancerpatienter.
Att koppla genstatus till funktion kräver komplex matematik och enorm datorkraft. Denna kunskap är väsentlig för att förutsäga resultatet av terapier som skulle blockera funktionen hos dessa gener. Så, hur kan vi avslöja de överlappande funktionerna för att förutse individuella resultat för patienter?
Vad Netflix kan lära oss
Lyckligtvis för oss har detta problem redan lösts i datavetenskap. Svaret är en klass av tekniker som kallas "matrixfaktorisering" - och du har sannolikt redan interagerat med dessa tekniker i ditt vardag.
2009, Netflix hade en utmaning att personifiera filmbetyg för varje Netflix-användare. På Netflix har varje användare en distinkt uppsättning betyg av olika filmer. Medan två användare kan ha liknande smaker i filmer, kan de variera vildt i specifika genrer. Därför kan du inte förlita dig på att jämföra betyg från liknande användare.
I stället hittar en matrisfaktoreringsalgoritm filmer med liknande betyg bland en mindre grupp användare. Användargruppen kommer att variera för varje film. Datorn associerar varje användare med en grupp filmer i en annan utsträckning, baserat på deras individuella smak. Relationerna mellan användare kallas "mönster". Dessa mönster lärs av data och kan hitta vanliga rankningar som inte är förutspådda av enbart filmgenrer - till exempel kan användarna dela en preferens för en viss regissör eller skådespelare.
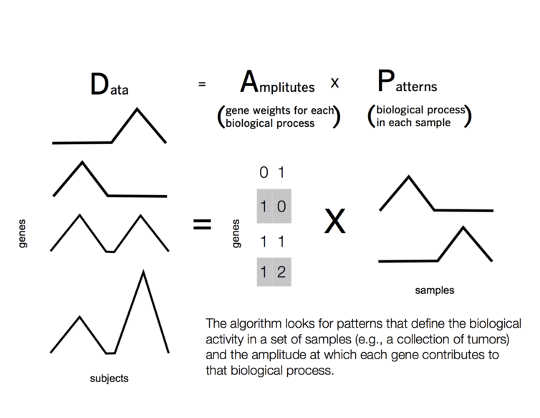 Genevieve Stein-O'Brien, CC BY
Genevieve Stein-O'Brien, CC BY
Samma process kan fungera i cancer. I detta fall är mätningarna av gendysregulering analog med filmvärderingar, filmgenrer till biologisk funktion och användare till patienternas tumörer. Datorn söker över patienttumörer för att hitta mönster i gendysregulering som orsakar den maligna biologiska funktionen i varje tumör.
Från filmer till tumörer
Analysen mellan filmbetyg och cancergenetik bryts ner i detaljerna. Om inte de är minderåriga, är Netflix-användare inte tvungna i filmerna som de tittar på. Men våra kroppar föredrar istället att minimera antalet gener som används för en enda funktion. Det finns också stora uppsägningar mellan gener. För att skydda en cell kan en gen lätt ersätta en annan för att tjäna en gemensam funktion. Genfunktioner i cancer är ännu mer komplexa. Tumörer är också mycket komplexa och utvecklas snabbt beroende på slumpmässiga interaktioner mellan cancercellerna och det närliggande hälsosamma organet.
För att ta hänsyn till dessa komplexiteter har vi utvecklat en matrixfaktoriseringsmetod som heter Koordinerad genaktivitet i mönsteruppsättningar - eller CoGAPS för korta. Vår algoritm står för biologins minimalism genom att införliva så få gener som möjligt i mönstren för varje tumör.
Olika gener kan också ersätta varandra, var och en tjänar en liknande funktion i ett annat sammanhang. För att beräkna detta beräknar CoGAPS samtidigt en statistik för de så kallade "mönster" av genfunktionen. Detta gör att vi kan beräkna sannolikheten för att varje gen används i varje biologisk funktion i en tumör.
Till exempel tar många patienter en målinriktad terapeutisk kallad cetuximab för att förlänga överlevnaden i kolorektal, bukspottskörtel, lung och orala cancerformer. Vårt senaste arbete har visat att dessa mönster kan särskilja genfunktion i cancerceller som svarar mot det målmedicinska läkemedlet cetuximab från de som inte gör det.
Framtiden
Tyvärr kan cancerterapier som riktar sig gener generellt inte bota en patients sjukdom. De kan bara fördröja utvecklingen i några år. De flesta patienter återfall sedan, med tumörer som inte längre svarar mot behandlingen.
Vårt eget senaste arbete fann att de mönster som skiljer genfunktionen i celler som är mottagliga för cetuximab inkluderar de mycket gener som ger upphov till resistens. Emerging immunotherapies är lovande och verkar bota vissa cancerformer. Men alltför ofta återkommer patienter med dessa behandlingar också. Ny data som spårar cancergenetiken efter behandling är avgörande för att avgöra varför patienter inte längre svarar.
Tillsammans med dessa uppgifter kräver cancerbiologi också en ny generation vetenskapsmän som kan överbrygga matematik och statistik för att bestämma de genetiska förändringar som uppträder över tiden i drogmotstånd. På andra områden inom matematik kan dataprogrammen förutse långsiktiga resultat. Dessa modeller används vanligen i väderprognos och investeringsstrategier.
I dessa fält och Min egen tidigare forskning, har vi funnit att uppdateringar till modellerna från stora dataset - t.ex. satellitdata vid väder - förbättrar långsiktiga prognoser. Vi har alla sett effekten av dessa uppdateringar, med väderförutsägelser förbättras desto närmare är vi på storm.
Precis som verktyg från datavetenskap som används kan anpassas till både filmrekommendationer och cancer, kommer den framtida generationen av beräkningsforskare att använda prediktionsverktyg från en rad områden för precisionsmedicin. I slutändan hoppas vi med dessa beräkningsverktyg kunna förutse tumörers reaktion på terapi så vanligt som vi förutsäger vädret, och kanske mer tillförlitligt.
Om författaren
Elana Fertig, biträdande professor i onkologi biostatistik och bioinformatik, Johns Hopkins University
Den här artikeln publicerades ursprungligen den Avlyssningen. Läs ursprungliga artikeln.
relaterade böcker
at InnerSelf Market och Amazon



















