

Twitter har sedan sin offentliga lansering 10 år sedan använts som en social nätverksplattform bland vänner, en snabbmeddelandeservice för smartphoneanvändare och ett marknadsföringsverktyg för företag och politiker.
Men det har också varit en ovärderlig källa till data för forskare och forskare - som jag själv - som vill studera hur människor känner och fungerar inom komplexa sociala system.
Genom att analysera tweets har vi kunnat observera och samla in data om de sociala interaktionerna hos miljontals människor "i naturen", utanför kontrollerade laboratorieexperiment.
Det har gjort det möjligt för oss att utveckla verktyg för övervakning av kollektiva känslor av stora populationer, hitta lyckligaste ställen i USA och mycket mer.
Så hur, blev Twitter så en unik resurs för beräkningssociala forskare? Och vad har det gjort att vi kan upptäcka?

Twitters största gåva till forskare
I juli 15, 2006, Twittr (som det var känt) publicly lanserades som en "mobiltjänst som hjälper grupper av vänner studsa slumpmässiga tankar runt med sms." Möjligheten att skicka gratis 140-teckengruppstexter körde många tidiga adoptrar (medföljer mig) för att använda plattformen.
Med tiden, antalet användare exploderad: från 20 miljoner i 2009 till 200 miljoner i 2012 och 310 miljoner idag. Snarare än att kommunicera direkt med vänner, skulle användarna helt enkelt berätta för sina anhängare hur de kände, svara positivt eller negativt på nyheter eller spricka skämt.
För forskare har Twitters största gåva varit att tillhandahålla stora mängder öppen data. Twitter var ett av de första stora sociala nätverk för att tillhandahålla dataprover genom något som kallas Application Programming Interfaces (API), vilket gör det möjligt för forskare att fråga Twitter för specifika typer av tweets (t.ex. tweets som innehåller vissa ord), liksom information om användare .
Detta ledde till en explosion av forskningsprojekt som utnyttjade dessa data. Idag producerar en Google Scholar-sökning efter "Twitter" sex miljoner träffar, jämfört med fem miljoner för "Facebook". Skillnaden är särskilt slående, eftersom Facebook har ungefär fem gånger så många användare som Twitter (och är två år äldre).
Twitters generösa datapolitik ledde utan tvekan till enastående fri publicitet för företaget, som intressanta vetenskapliga studier fick hämtas av de vanliga medierna.
Studera lycka och hälsa
Med traditionell folkräkning data långsam och dyr att samla, öppna dataflöden som Twitter har potential att tillhandahålla ett realtidsfönster för att se förändringar i stora populationer.
University of Vermont s Computational Story Lab grundades i 2006 och studerar problem inom tillämpad matematik, sociologi och fysik. Sedan 2008 har Story Lab samlat in miljarder tweets via Twitters "Gardenhose" -matning, ett API som strömmar ett slumpmässigt urval av 10-procent av alla offentliga tweets i realtid.
Jag tillbringade tre år på Computational Story Lab och hade tur att vara en del av många intressanta studier med hjälp av dessa data. Till exempel utvecklade vi en hedonometer som mäter Twittersphereens lycka i realtid. Genom att fokusera på geolocated tweets skickade från smartphones kunde vi karta de lyckligaste platserna i USA. Kanske överraskande fann vi Hawaii är den lyckligaste staten och vinodling Napa den lyckligaste staden för 2013.
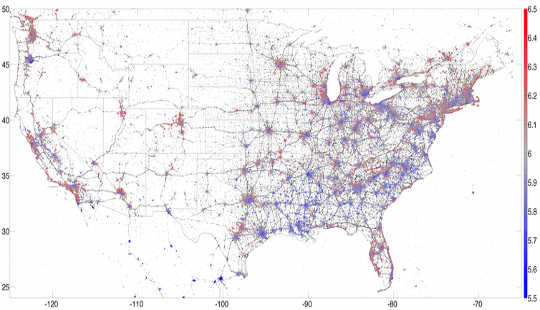 En karta över 13 miljoner geolokerade amerikanska tweets från 2013, färgad av lycka, med rött indikerande glädje och blå indikerande sorg. PLoS ONE, Författare tillhandahållenDessa studier hade djupare tillämpningar: Korrelering av Twitter-ordanvändning med demografi hjälpte oss att förstå underliggande socioekonomiska mönster i städer. Till exempel kan vi länka ordanvändning med hälsofaktorer som fetma, så vi byggde en lexicocalorimeter att mäta "kaloriinnehållet" i sociala medier. Tweets från en viss region som nämnde högkalorivaror ökade "kaloriinnehållet" i den regionen, medan tweets som nämnde träningsaktiviteter minskade vår mätvärde. Vi fann att denna enkla åtgärd korrelerar med andra hälso- och välfärdsmetod. Med andra ord kunde tweets ge oss en ögonblicksbild vid en viss tidpunkt av den totala hälsan i en stad eller region.
En karta över 13 miljoner geolokerade amerikanska tweets från 2013, färgad av lycka, med rött indikerande glädje och blå indikerande sorg. PLoS ONE, Författare tillhandahållenDessa studier hade djupare tillämpningar: Korrelering av Twitter-ordanvändning med demografi hjälpte oss att förstå underliggande socioekonomiska mönster i städer. Till exempel kan vi länka ordanvändning med hälsofaktorer som fetma, så vi byggde en lexicocalorimeter att mäta "kaloriinnehållet" i sociala medier. Tweets från en viss region som nämnde högkalorivaror ökade "kaloriinnehållet" i den regionen, medan tweets som nämnde träningsaktiviteter minskade vår mätvärde. Vi fann att denna enkla åtgärd korrelerar med andra hälso- och välfärdsmetod. Med andra ord kunde tweets ge oss en ögonblicksbild vid en viss tidpunkt av den totala hälsan i en stad eller region.
Med hjälp av riktigheten av Twitter-data har vi också kunnat se människors dagliga rörelsemönster i aldrig tidigare skådad detalj. Förståelse för mänskliga rörlighetsmönster har i sin tur kapacitet att omvandla sjukdomsmodellering, öppna upp det nya fältet digital epidemiologi.
För andra studier tittade vi på huruvida resenärer uttrycker större glädje på Twitter än de som bor hemma (svara: de gör) och om glada individer tenderar att hålla sig i ett socialt nätverk (igen gör de). Verkligen, positivitet verkar vara bakad i själva språket, i den meningen att vi har mer positiva ord än negativa ord. Detta var inte fallet bara på Twitter men över en mängd olika media (t.ex. böcker, filmer och tidningar) och språk.
Dessa studier - och tusentals andra som dem från hela världen - var bara möjliga tack vare Twitter.
De kommande 10-åren
Så vad kan vi förvänta oss att lära oss av Twitter under de kommande 10-åren?
Några av de mest spännande arbeten innebär för närvarande att man kopplar sociala medier med matematiska modeller för att förutse fenomen på populationsnivå som sjukdomsutbrott. Forskare har redan haft en viss framgång i att öka sjukdomsmodeller med Twitter-data för att prognostisera influensa, särskilt FluOutlook plattform som utvecklats av nordöstra universitetet och institutet för vetenskapligt utbyte.
Fortfarande kvarstår ett antal utmaningar. Sociala medier data lider av en mycket låg "signal-till-brus-förhållande." Med andra ord, de tweets som är relevanta för en viss studie drunknar ofta av irrelevant "buller".
Därför måste vi ständigt vara medvetna om vad som har kallats "stor datahubris"När vi utvecklar nya metoder och inte överbekämpar våra resultat. Förbundet med detta borde vara målet att producera tolkbara "glaslåda" förutsägelser från dessa data (i motsats till "black-box" förutsägelser, där algoritmen är gömd eller ej klar).
Sociala media data är ofta (ganska) kritiserade för att vara en liten, icke representativt prov av den bredare befolkningen. En av de stora utmaningarna för forskare är att räkna ut hur man redogör för sådana skevda data i statistiska modeller. Medan fler människor använder sociala medier varje år, vi måste fortsätta försöka förstå biaserna i dessa data. Till exempel tenderar uppgifterna fortfarande att överrepresentera yngre individer på bekostnad av äldre populationer.
Först efter att ha utvecklat bättre biaskorrigeringsmetoder kommer forskarna att kunna göra fullständiga självsäkra förutsägelser från tweets.
Om författaren
Lewis Mitchell, föreläsare i tillämpad matematik, University of Adelaide
Den här artikeln publicerades ursprungligen den Avlyssningen. Läs ursprungliga artikeln.
relaterade böcker
at InnerSelf Market och Amazon




















